Source: https://blog.makersacademy.com/demystifying-blockchain-in-8-days-part-1-a22e8eda37ce
by
For our final project at Makers our project team was united by our desire to complete a technical project. We had very different opinions on what this represented though. Some people expressed interest in developing prototypal programming languages. There were also discussions about developing compilers, web browsers and machine-learning driven chat rooms.



by
For our final project at Makers our project team was united by our desire to complete a technical project. We had very different opinions on what this represented though. Some people expressed interest in developing prototypal programming languages. There were also discussions about developing compilers, web browsers and machine-learning driven chat rooms.
After around 45 minutes of
discussions we decided to build a blockchain based product. We all shared
several reasons for going in this direction. All of us wanted to demystify a
technology that is not well understood and has become wrapped up in
cryptocurrency hysteria. The process of building a blockchain also presented a
sufficiently technical challenge to pique everybody’s interest in the group.
Once the initial product — an array that would detect if an index was altered
after creation — was developed, there was also considerable scope to expand the
blockchain and eventually we incorporated the blockchain algorithm we wrote
into a web app.
This allowed us to apply the web
development skills we picked up at Makers to the project. We eventually
incorporated the blockchain into a prescription management application.
I’ll go into more detail on this in
part two. The final product illustrated how blockchain technology could be used
to prevent prescription fraud and store a secure record of patient
prescriptions that were authorised by doctors.
What
Is A Blockchain?
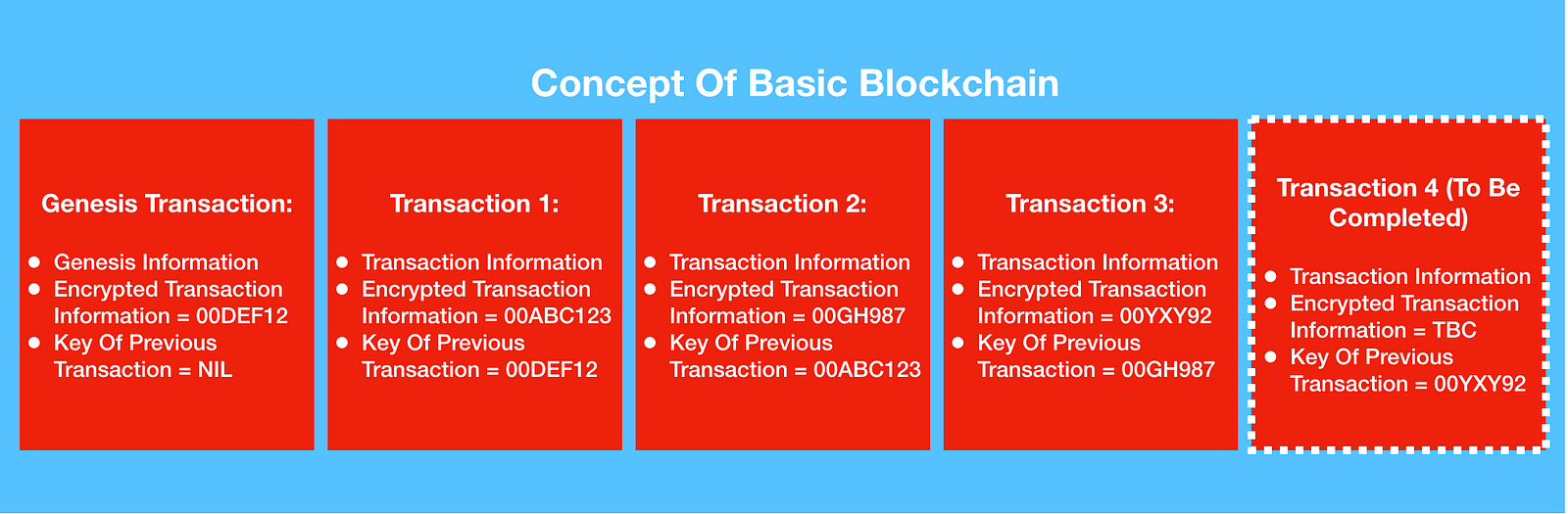
At the very core, a blockchain is a
ledger, or record of transactions that is secure. The diagram below shows the
basic data that each block contains.
Blockchains can be used to store any
types of transactions. These can be financial transactions like the purchase of
property or financial instruments. They can also be social transactions, like
votes for political candidates. Whenever a new transaction is added to the
blockchain the transaction becomes encrypted. The encrypted transaction then
becomes the unique key or ID for each block. When a new block is added to the
blockchain, in addition to encrypting it’s own data it also stores the key of
the previous transaction. Every new block in the chain points to the preceding
block except for the genesis transaction, which simply is used to signify the
beginning of the blockchain.
The security of the blockchain rests
on two pillars. The first pillar is the fact that all the data is encrypted.
Only those who have access to the encryption key can review the data. The
second (and more interesting) pillar of security lies in the blocks themselves.
Every block contains the previous
blocks encryption key (which is also referred to as a hash). You can loop
through and compare the previous key of the subsequent key of the current
block. If they are not equal then you know that one of the blocks has been
changed post creation and the security of the blockchain has been compromised.
Unlike user authentication, where passwords are encrypted when they are sent to
databases, and decrypted when the user logs in, the hash remains permanently
encrypted. If any index or record or in the blockchain is modified, then a new
hash is generated from the modified data.
Building
& Testing The Basic Blockchain
Once we understood the basic
principles of a blockchain we realised, in algorithmic terms, that the
blockchain could be represented by an array of encrypted objects that held the
unique encryption of the previous object. We decided to develop this using
NodeJS for a number of reasons. Our group were all familiar with JavaScript
from the Makers course and understood that JavaScript is a flexible programming
language that we could use throughout our application. The NodeJS ecosystem is
also incredibly exciting and there are great tutorials and libraries that we
used to support the development of the project.
We took an Object-Orientated (OO)
approach to the project and began by creating and testing block objects. OO
JavaScript was used due to our familiarity with OO programming and testing.
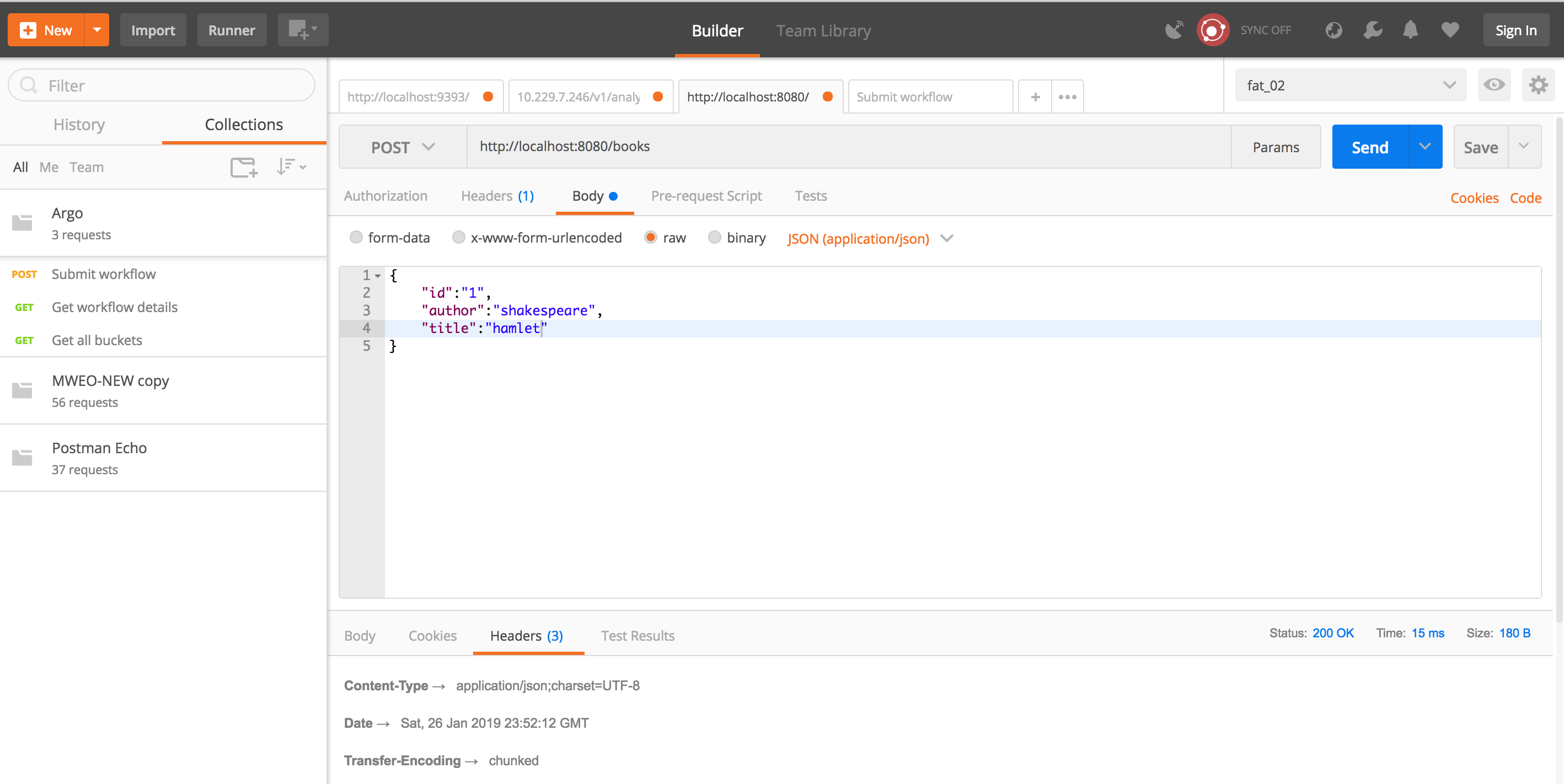
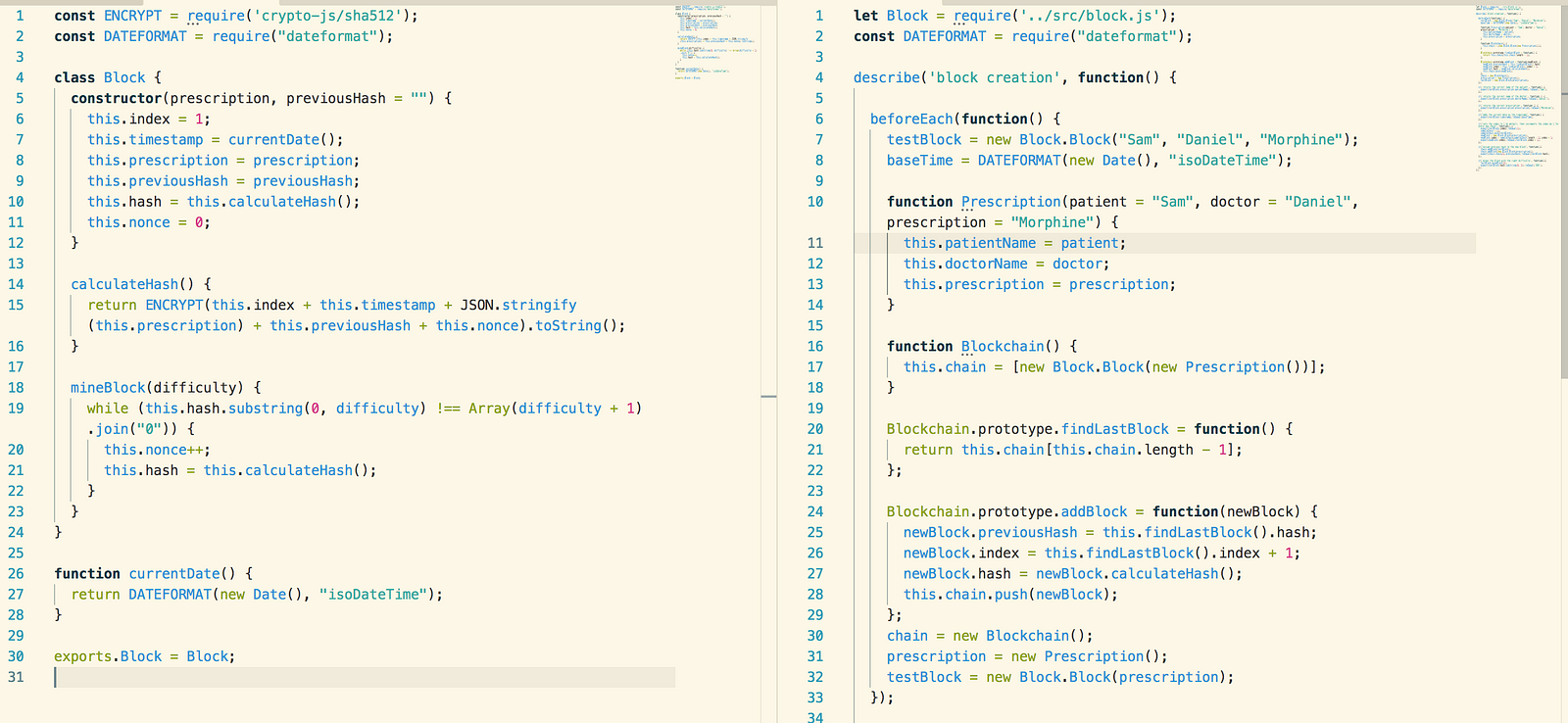
Block Object Testing
The screenshot below is a screenshot
of the Block object that we created and the basic tests we used. The
prescription object is created separately and is simply three strings.
To test the block objects were being
successfully created we created a fake Blockchain object (or double). The fake
Blockchain only has the functionality for adding additional blocks to the
chain. This is just enough functionality to enable us to test that new blocks
contain the hash generated upon the creation of the previous block.
To test that the hashing is working
we pass in two blocks to the Blockchain double, then compare that the previous
hash of the block at index 2 is equal to the hash of the block at index 1.
We also test that the hash
generation function calculates hashes at the stated complexity. The mineBlock
function uses the “nonce” variable to determine the complexity of the
encryption.
The “nonce” is used to determine the
number of 0s that each hash must begin with. The greater number of 0s, the more
computational resources are required to generate a hash as the hash generator
will keep running until the encrypted string has the correct number of 0s.
We tested this by passing a
difficulty/nonce value of 3 and mine the block. We then ensure that the
encrypted string begins with the same number of 0s as the nonce.
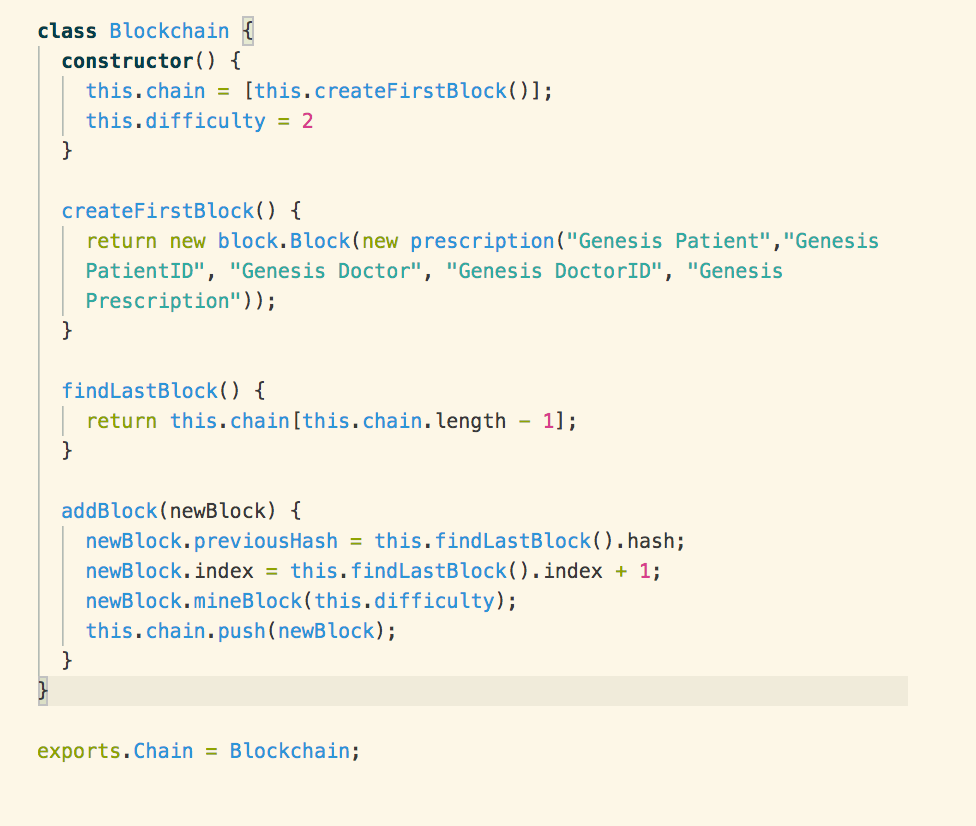
Chain Object Testing
Below is a screenshot of the
Blockchain that is used to store the blocks.
The first thing we ensure is that
the create genesis/first block method is working as intended. This is achieved
through a simple (and slightly self-referential test) that the function returns
the same value as the first element in the blockchain.
From there it’s a simple case of
testing that the add block and return last block methods do actually return the
correct blocks:
In the algorithm most of the
functionality is delegated to the block objects. The role of the chain is very
simple; the chain simply creates a genesis block as a reference point, adds new
blocks and has the capacity to return the last block.
Ensuring the blockchain is valid is
delegated to a validity checker object.
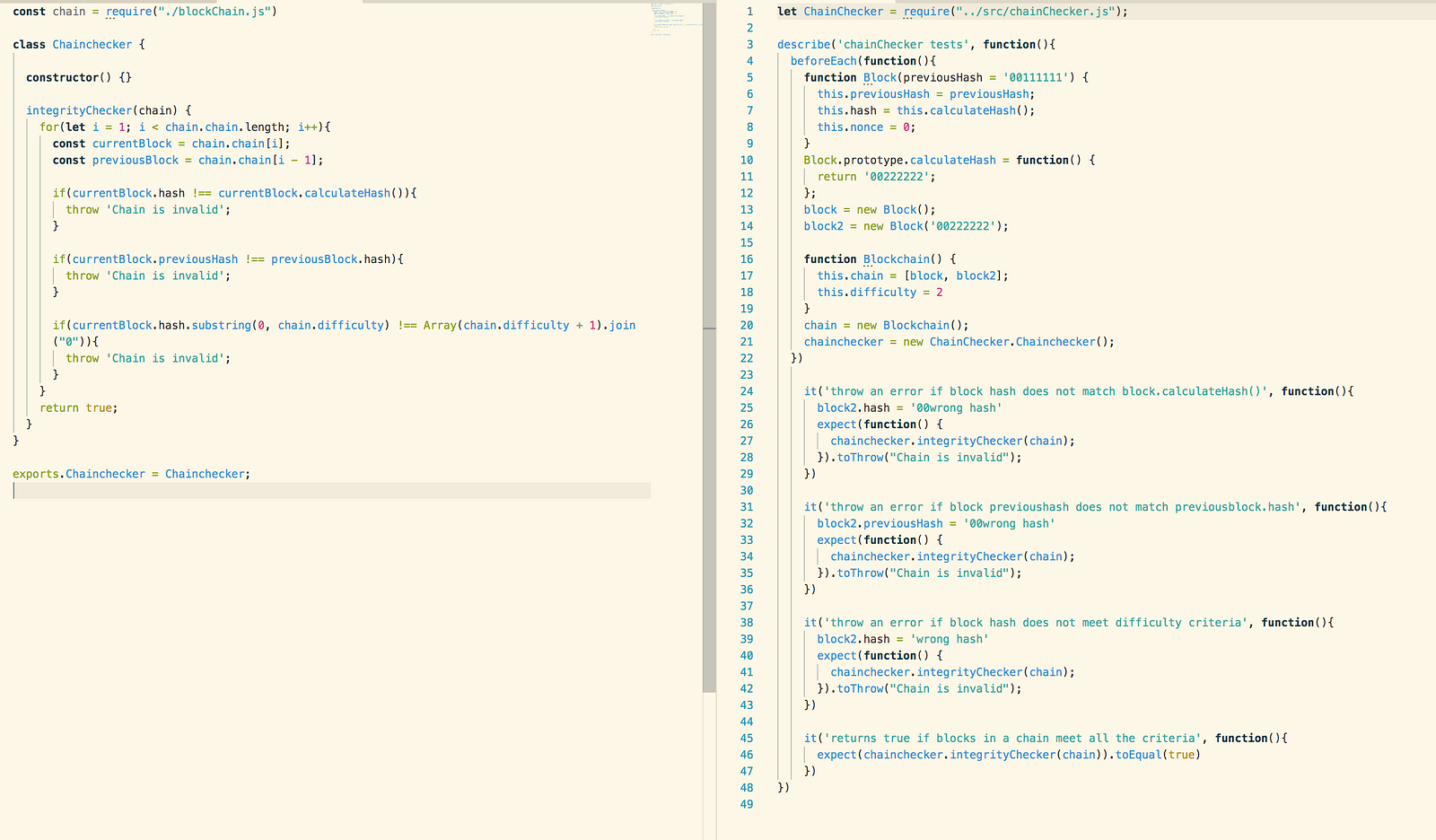
Validity Testing
The final object that makes up the
core of the blockchain is the validity checker object. The validity checker
receives the array of block items as an argument and loops through all the
blocks in the array. The loop begins at index 1, and also selects the block in
the preceding index. If the previous hash variable in the “current block” does
not match the current hash of the previous block then the security of the
blockchain has been compromised.
This was tested by creating a double
blockchain that was composed of double block objects. We then went through and
changed elements inside the objects to test the following scenarios:
- The current block has been compromised
- The previous block has been compromised
- The blockchain is valid
Having the three components of the
blockchain separated out into different objects made it easier to test that
each object was demonstrating the correct behaviours that we expected. It also
allowed us to develop more functionality for the blockchain with confidence as
we knew that the core product was fully tested and devoid of bugs.
This confidence enabled our team to
extend out the blockchain algorithm into a full-stack web application. We
decided to use pharmaceutical prescriptions to illustrate how the blockchain
could be deployed to the web, and how it could be used to solve real-world
problems.
In the follow-up article, I’ll
discuss how we incorporated the blockchain into a full-stack web application.
The web application is very interesting as we created two different user types,
and set different authorisation levels to represent how the blockchain could be
used by different users.
**If you want to review the code, here it is! **