Developers should constantly be seeking to learn new skills, and one of those is localization. Learn more about what localization is and does here.
Being a developer you understand that to grow you need to be always learning, whether from books, visiting conferences, or reading articles like this one. Among the new essential skills, you should be acquiring right now is rightfully placed the ability to build software that supports localization.
Localization is basically adapting software to be easily consumed in different languages and locales. Any person around the world, speaking any language could start using your app, making orders from your website, or playing the game you developed in their native language. Just imagine how many more customers your software would get. Expanding target markets for your product is a big deal and if you could make that happen you’d be more valuable as a developer.
In this article, I will tell you what exactly you should know about developing software that could support multiple languages and locales with no translations needed (unless you wish to). After discussing things with my fellow developers at Crowdin, I wish somebody told them about localization sooner, so I’ve come up with 5 tips about localization you should also know. Keep on reading if you want to extend your resume with a new skill that you can learn right now – building software ready for localization.
1. Add Basic Support for Localization Right from The Start
Most likely, support for only 1 language will not be enough at some point. So you better be prepared for what is to come. Especially if there’s already a plan of taking the product globally – be sure to discuss that with the project manager or the customer directly before you even start writing the code. If you don’t prepare from the start, you’ll have to spend extra time refactoring all the code to make it support localization later. So better do your initial prep work for localization now.
Of course, there are 360 million native English speakers and one of the half a billion people who speak English as a second language. But what about people who don’t speak English? There are almost 1.2 billion Chinese native speakers, about 400 million Spanish speakers, and many more people speaking other world languages according to Babble-on. So, supporting several languages is not something extra anymore, it’s something people expect from your product.
2. Externalize All the Localization Resources
You wouldn’t want to be looking for the text strings and retrieving them from the code manually to pass them to translators. Instead, think of some faster and easier solution like localization text wrappers or using keys as an alternative to the hardcoded texts.
For example, in the Android development you can use Resources::getString and format your strings in the following way:
res/values/strings.xml
res/values-ua/strings.xml
In this case, you’ll receive:
The advised solution here is to use unique string keys and store the actual text strings in a separate file for each language. Create a separate file or directory for each locale your product is going to support. For every file localized, place the translated version to exactly the same path relative to the root and give the same name as original file plus the locale identifier.
For example, Android uses files with the “.xml” file extension to keep and fetch all the strings used within the app, for each supported language. A simple method call in your code will lookup and return the requested string based on the current language in use on the device.
You’ll have to place all the texts in the default language you’re using, let’s assume it’s English, into
res/values-en/strings.xml.
Then you’ll be able to specify several
res/<qualifiers>/ directories with different qualifiers. Each for a corresponding language and locale. This way, to get the French version of the file your app will look in res/values-fr/strings.xml, and for the Spanish version of the file, it will look in res/values-es/strings.xml.3. Add Localization Comments
Translators who will later have to work with the strings file you provided, usually do not get much additional context with the file. So adding descriptive comments in some cases might help them a lot.
Consider adding comments in the following cases:
- The string might come out ambiguous. For example “Bookmark” might be both a noun and a verb, and that’s something difficult to guess without context. In this case, a descriptive string key also helps, for example instead of:
it’s better to use
- If the string contains a variable – add an example or a short explanation of what might it be.
You should also consider that every platform has an established format for localization comments, so make sure you research and follow it. As there are a lot of automated tools like Crowdin, that might later parse these comments for easier access and use by translators.
4. Use Localization Libraries to Simplify the Process
Each language has its own specifics for the text layout, formatting, and more. That’s the work you don’t have to do manually as it’s easily automated. It’s highly recommended to use localization libraries (for example, you can use International Components for Unicode (ICU)) that will help you with handling the following aspects:
- support for right-to-left (RTL) and left-to-right (LTR) scripts in the same string
- applying numeric, currency, date and time format strings. For example, the date format changes based on the language, for English it’s
7/23/2018(en-US) and for French, it’s23/07/2018(fr-FR) - Usage of plurals. Examples:
5. Set up An Integration with A Localization Management Platform
Once your customer is ready to localize the software you’ve built, you’ll need to export all the localizable text into some common file format that will be passed to the team of translators. Some companies still do localization with Excel files. But let me stop you here, don’t do localization in Excel. That’s an amazing tool, but for other great things. Just imagine for a second how making sure that all the strings in the .xls or .xlsx file are up-to-date and all the translations are in sync with your code would look like. What if your product is updated monthly/weekly/daily? Trust me, you wouldn’t like dealing with that manually.
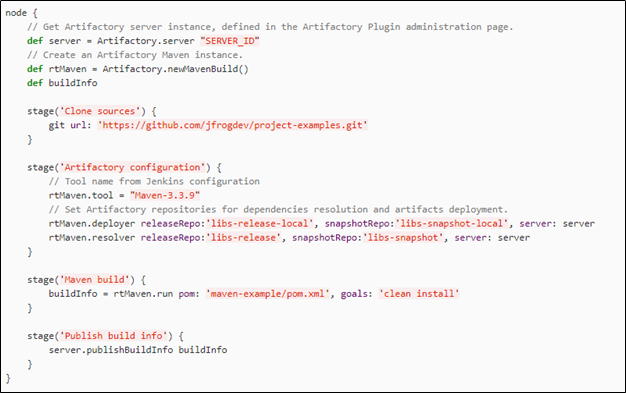
That’s why most companies automate all these mundane text strings exchanges with integrations or in-house tools. For example, you can set up API or Git integration with a localization management platform. Once you set up the integration, our tool will get the localization files from your repo and upload them to the Editor, where strings will look user-friendly with the comments you provided. Once the translations are made the system combines them into a file and syncs them with your code as a merge request or as a file that can be added to the directory for a specific locale.
Conclusion
Software localization is a great way to extend your product’s target markets as people are more likely to use the software in their native language. Localization is also something that is never done overnight, so hopefully, now you’ll be prepared as you already know the basics.
Originally published at Crowdin Blog.