Source: Simplified Blockchain Part 2: Ethereum Example With Java Client - DZone Security
Simplified Blockchain Part 2: Ethereum Example With Java Client
Simple example explaining how powerful blockchain is.
In the previous article, we got acquainted with the theoretical foundations of the blockchain. In this article, we implement the functionality of the passport office.
Before You Start
In order to generate and deploy smart contract, you need to install next tools:
- Solc — Solidity compiler: Solc download link
- Ganache-cli —Testing Ethereum network, to install execute:
npm install -g ganache-cli - Web3j — Tool to generate java client. to install execute next command in windows power shell:
Simplified Blockchain Part One: Theory
Source: Simplified Blockchain Part One: Theory - DZone Security
· Security Zone · PresentationBlockchain in Two Words
You can interpret blockchain as a distributed database, each node of which is launched on the client side. All nodes synchronize (validate and confirm) all transactions among themselves. Every deployed smart contract (code and variables) stays there forever with its unique id. Initially, blockchain was created as a way to store information about sending/receiving money between clients. New blockchain systems are significantly different — they let users deploy and execute functions + variables, also known as smart contracts. Smart contracts turned these databases into real, stateful servers.
Classical Server vs Blockchain Network
To simplify your understanding of blockchain, check out the figure and table below:

| Classic Java EE server | Blockchain network | |
| Is it decentralized? | No. Can be clustered (but still not decentralized) | Yes it's decentralized and all nodes synchronize the same state. |
| Is it possible to redeploy artifacts? | Each component (java class eg jar/war/ear) can be redeployed | Every new component (smart contract) is persisted forever with it's unique hash. Every new deploy create new version of the component |
| What I need to do to hack the application? | Put troyan inside deployed component/crack database/social engineering (bride server administrator) | In the best case you need to replace (half + 1 node) |
| Can persiste a lot of data? | Yes, often servers tons of hdd/ram memory | Each node has to replicate all the data. Big size nodes became useless quickly. Rather looks like text/transaction storage |
| Is it possible to brut force security once you have source code? | Depends on security implementation. Often it's possible. | No chance. To brutforce regular Ethereum account private key - billion years |
Key Advantages of Blockchain
Code can be trusted:
1. Each transaction executed on blockchain being verified by (half + 1) node. To falsify it, you need to falsify more than half of the nodes. This is practically impossible.
2. Each contract (also known as a class in Java) has its unique hash and can't be redeployed. An executed contract is the right contract you execute.
3. All transactions (a.k.a. blocks) in blockchain have a specific hash that is compatible with the next and previous transactions. Quite similar to GIT. So no transaction can be injected somewhere in the middle.
So if we deploy the same code twice, we can see unique transaction hash and unique contract address.
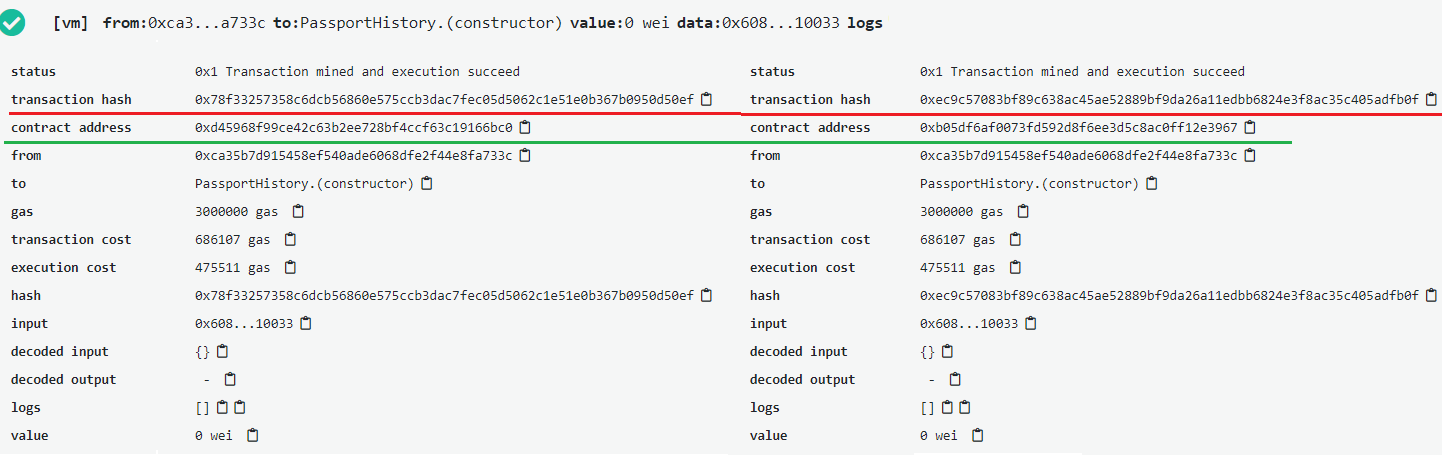
Access is invulnerable
Each contract is being executed by account (built in feature). Ethereum account key has 256 bit complexity. Brute force of such key takes more than a billions years.
When Blockchain Is Useful
Because of this, two advantages blockchain platforms can be used as trusted, incorruptible third-party player eg:
- Casino: blockchain protects casino by holding a bet and protect player from game falsification.
- Signing juridical contact: blockchain helps to sign contract by both sides in one single action and store that contract without any possible change. So you do not need the presence of a lawyer/realtor as evidence of the authenticity of the contract.
- Government systems: blockchain systems protected from any falsification (even bribed internal employees) and stays completely invaluable to attacks even if application been stolen.
Implementing Passport Office System on Blockchain
In Sweden, their national passport service is based on blockchain systems. Let's create the same simplified service using Ethereum in the next article.
Blockchain Implementation With Java Code
Source: Blockchain Implementation With Java Code - DZone Java
Let's take a look at a possible blockchain implementation using Java. We build up from first principles and develop some code to help show how it all fits together.
Bitcoin is hot — and what an understatement that is. While the future of cryptocurrency is somewhat uncertain, blockchain — the technology used to drive Bitcoin — is also very popular.
Blockchain has an almost endless application scope. It also arguably has the potential to disrupt enterprise automation. There is a lot of information available covering what and how blockchain works. We have a free whitepaper that goes into blockchain technology (no registration required).
This article will focus on the blockchain architecture; particularly, demonstrating how the "immutable, append-only" distributed ledger works with simplistic code examples.
As developers, seeing things in code can be much more useful in understanding how it works when compared to simply reading technical articles. At least that's the case for me. So, let's get started!
Blockchain in a Nutshell
Let's first give a quick summary of blockchain. A block contains some header information and a set or block of transactions of any type of data. The chain starts with a first (Genesis) block. As transactions are added/appended, new blocks are created based on how many transactions can be stored within a block.
When a block threshold size is exceeded, then a new block of transactions is created. The new block is linked to the previous block, hence the term blockchain.
Immutability
Blockchains are immutable because an SHA-256 hash is computed for transactions. A block's contents are also hashed which provide a unique identifier. Moreover, the hash from the linked, previous block is also stored and hashed in the block header.
This is why trying to tamper with a blockchain block is basically impossible, at least with current computing power. Here's a partial Java class definition showing the properties of the block.
Notice the injected generic type is of type Tx. This allows transaction data to vary. Also, the previousHash property will reference the previous block's hash. The merkleRoot and nonce properties will be described in a bit.
Block Hash
Each block can compute a block hash. This is essentially a hash of all the block's properties concatenated together, including the previous block's hash and a SHA-256 hash computed from that.
Here is the method defined in the Block.java class that computes the hash.
The block transactions are serialized to a JSON string so it can be appended to the block properties before hashing.
The Chain
The blockchain manages blocks by accepting transactions. When a predetermined threshold has been reached, then a block is created. Here is a SimpleBlockChain.java partial implementation:
Notice that the chain property holds a list of Blocks typed with a Tx type. Also, the no arg constructor creates an initial "genesis" block when the chain is created. Here is the source for the newBlock() method.
This new block method will create a new block instance, seed appropriate values, and assign the previous block's hash (which will be the hash of the head of the chain). It will then return the block.
Blocks can be validated before being added to the chain by comparing the new block's previous hash to the last block (head) of the chain to make sure they match. Here's a SimpleBlockchain.java method depicting this.
The entire blockchain is validated by the looping-over of the chain to ensure a block's hash still matches the previous block's hash.
Here is the SimpleBlockChain.java validate() method implementation.
You can see that trying to fudge transaction data or any other property in any way is very difficult. And, as the chain grows, it continues to get very, very, very difficult, essentially impossible — that is, until quantum computers are available!
Adding Transactions
Another significant technical point of blockchain technology is that it is distributed. The fact that they are append-only helps in duplicating the blockchain across nodes participating in the blockchain network. Nodes typically communicate in a peer-to-peer fashion, as is the case with Bitcoin, but it does not have to be this way. Other blockchain implementations use a decentralized approach, like using APIs via HTTP. However, that is a topic for another article.
Transactions can represent just about anything. A transaction could contain code to execute (i.e Smart Contract) or store and append information about some kind of business transaction.
Smart contract: Computer protocol intended to digitally facilitate, verify, or enforce the negotiation or performance of a contract.
In the case of Bitcoin, a transaction contains an amount from an owner's account and amount(s) to other accounts (e.g. transferring Bitcoin amounts between accounts). The transaction also includes public keys and account IDs within it, so transferring is done securely. But that's Bitcoin-specific.
Transactions are added to a network and pooled; they are not in a block or the chain itself.
This is where a blockchain consensus mechanism comes into play. There are a number of proven consensus algorithm and patterns beyond the scope of this article.
Mining is a consensus mechanism that Bitcoin blockchains use. That is the type of consensus discussed further down this article. The consensus mechanism gathers transactions, builds a block with them, and then adds the block to the chain. The chain then validates the new block of transactions before adding to the chain.
Merkle Trees
Transactions are hashed and added to the block. A Merkle Tree data structure is created to compute a Merkle Root hash. Each block will store the root of the Merkle tree, which is a balanced binary tree of hashes where interior nodes are hashes of the two child hashes, all the way up to the root hash, which is the Merkle Root.

This tree is used to validate the block transactions. If a single bit of information is changed in any transaction, the Merkle Root will be invalid. Also, they can help with transmitting blocks in a distributed fashion, since the structure allows only a single branch of transaction hashes required to add and validate the entire block of transactions.
Here's the method in the Block.java class that creates a Merkle Tree out of the transaction list.
This method is used to compute a Merkle Tree root for the block. The companion project has a Merkle Tree unit test that attempts to add a transaction to a block and verify that the Merkle Roots have changed. Here is the source code for the unit test.
This unit test emulates validating transactions, then changing a transaction in a block outside of the consensus mechanism, e.g. if someone tries to change transaction data.
Remember, blockchains are append-only, and as the blockchain data structure is shared between nodes, block data structure (including the Merkle Root) are hashed and connected to other blocks. All nodes can validate new blocks and existing blocks can be easily proved as valid. So, a miner trying to add a bogus block or a node attempting to adjust older transactions are effectively not possible before the sun grows to a supernova and gives all a really nice tan.
Mining Proof of Work
The process of combining transactions in into a block, then submitting it for validation by members of the chain, is referred to as "mining" in the Bitcoin world.
More generally, in blockchain speak, this is called consensus. There are different types of proven distributed consensus algorithms. Which mechanism to use is based upon whether you have a public or permissioned blockchain. Our white paper describes this more in depth, but this article is focusing on the blockchain mechanics, so this example we will apply a proof-of-work consensus mechanism.
So, mining nodes will listen for transactions being executed by the blockchain and will perform a simple mathematical puzzle. This puzzle produces block hash with a predetermined set of leading zeros using a nonce value that is changed on every iteration until the leading zero hash is found.
The example Java project has a Miner.java class with a proofOfWork(Block block) method implementation, as shown below.
Again, this is simplified, but the miner implementation will perform a proof-of-work hash for the block once a certain number of transactions have been received. The algorithm simply loops and creates an SHA-256 hash of the block until the leading number hash is produced.
This can take a lot of time, which is why specific GPU microprocessors have been implemented to perform and solve this problem as fast as possible.
Unit Tests
You can see all these concepts pulled together with the Java example project's JUnit tests available on GitHub.
Give this a run. It will let you check out how this simple blockchain works.
Also, if you are a C#'er reading, this (we won't tell anyone), we also have these same examples written in C#. Here is the link to the example C# blockchain implementation.
Final Thoughts
Hopefully, this post has provided you enough interest and insight to keep researching blockchain technology.
All of the examples introduced in this article are used in our in-depth blockchain white paper (no registration required to read). These same examples are in more detail in the white paper.
Also, if you want to see a full blockchain implementation in Java, here's a link to the open-source BitcoinJ project. You'll see these concepts in action in a real production implementation.
If so, next recommended learning steps are to check out a more production-based open-source blockchain framework. A good example is HyperLedger Fabric. That will be the subject of my next article — stay tuned!